If There is a Decision to be Made, there is Risk for Bias
In the last decade, advances in data science and engineering have made possible to develop various data products across the industry. Problems that not so long ago were treated as very difficult for machines to tackle are now solved (to some extent) and available at large scale capacities.
These include many perceptual-like tasks in computer vision, speech recognition, and natural language processing (NLP). Nowadays, we can contract large-scale deep learning-based vision systems that can recognize and verify faces on images and videos. In the same way, we can take advantage of large-scaled language models to build conversational bots, analyze large bodies of text to find common patterns, or use translation systems that can work on nearly any modern language. All this, just one click away.
It does not stop there. Machine learning systems are being used to decide if someone should receive loans from a bank, send people to jail, or determine the optimal locations where extra police force should be sent.
Though many people see these late advances as a good thing (and in fact, they could be), there is a problem that can easily outweigh the possible benefits of each of these solutions. A problem that relates to our deepest social issues and can show up on pretty much any stage of a machine learning project lifecycle.
That is the problem of bias.
To begin our discussion, it is important to understand that bias is a vast topic, and it does not necessarily relate to machine learning development. Here, we are going to focus on how bias can infiltrate machine learning systems, in various stages of development. However, bias in technology can happen anywhere and a clear example dates back to the 70s, when the first cameras and microphones were being developed.
To have an idea, pictures of black people did not look as good as pictures of white people simply because engineers and stakeholders decided to use white skin as a measure of quality. The story is very well told on this article from the New York Times by Sarah Lewis: The Racial Bias Built Into Photography. Long story short, to develop color-film technology, lab-technicians would use a photo of a white woman with brown hair as a measure of quality to calibrate the colors on the pictures. This picture is well known as a Shirley card and you can see it below.

Shirley Card
Similarly, the first microphones and speakers were not good at capturing the tonality difference between men and women.
If we think about it, these racial biases were built into the algorithms through deliberate decisions made by the hardware engineers responsible for developing these technologies. Just like camera engineers chose to use a white woman with red hair as a measure of goodness, audio engineers took deliberate decisions to optimize the microphones to better capture voice tonalities of men.
In other words, anytime that a decision needs to be taken by a human, bias can and probably will happen.
To get into machine learning development and how bias can be a major factor in it, let’s consider a simplified machine learning lifecycle.
A typical machine learning lifecycle might start with a Scoping stage. At this point, an important decision to be made by the analysts regards the level of performance the machine learning system should have. The machine learning team, along with the stakeholders involved, should decide on a metric to be used as a measure of success. This metric is essential to define baselines and to compare different versions of the same algorithm. Here, there is a decision to be made.
If we think about it, there are many performance metrics to choose from. For instance, for a simple classification system, one might choose among precision, recall, f1-score, accuracy, etc. Here, if the team chooses a metric like classification accuracy, they also need to be aware of the assumptions that come with it. In other words, if we decide to use accuracy as our metric, it is important to make sure that the existing groups and subgroups embedded in the data are well represented in terms of observations. If that is not the case, a simple classifier will try to minimize the average training error (or maximize average classification) as it can, which may neglect some subgroups in the data in exchange for better overall performance.
In a different situation, if the development team chooses precision as the primary metric, a different set of assumptions needs to be considered. That is because precision is a good metric when the cost of a false positive is much higher than the cost of a false negative. For instance, in an email spam filtering application, it is acceptable to see a spam email in the primary box (false negative) once in a while. However, it can be disastrous to have a good email (maybe an important one) sent to the spam box (false positive).
Advancing one step further in the machine learning life cycle, we come to the data collection, preparation, and feature engineering stages. These are probably the stages where there is the highest number of decisions to be made by the data analyst. For instance, when collecting data, it is crucial to ensure that all the groups (being that racial or gender) are well represented. If that is not the case, we might see bizarre results such as the ones below.

These results were generated by a Generative Adversarial Network (GAN) called Pulse. Pulse is a super-resolution deep learning model. It takes an image with low-resolution as input and constructs a high-resolution version of it. The problem here is that when Pulse receives a low-resolution image from a black person, like Barack Obama, it does its job (turns the low-resolution image into a high-resolution version). However, in the process, it removes the visual features that characterize black people and adds characteristics of ordinary white people.

And the issue is not with black people alone. From these few examples, we can also see bias towards asian people as well.

Unfortunately, we can see a very similar problem on large language models that learn word embeddings. You can think of word embeddings as a technique to represent words and their meanings through dense vectors. For each existing word in a given language, a language model such as BERT, learns a corresponding dense vector that encapsulates the meaning of that word. These vectors capture semantic context and can encapsulate relationships between words such as man/woman and king/queen. Word embeddings are one of the most revolutionary and successful ideas in natural language processing. Nowadays, it is almost inconceivable to think about solving NLP-related tasks without using word embeddings.
However, like any other method that learns from data, word embeddings are not immune to biases. To understand the issues, we need to consider two factors regarding how artificial intelligence researchers train these word embedding models. First, nowadays, language models are deep neural networks. These machine learning models are extremely good at learning correlations from data. Second, to train such systems, we use enormous bodies of text found on the internet, such as Wikipedia articles. One important point to consider here is that these bodies of texts are written by humans, and therefore are correlated with our views of the world. Now, linking the two points, if these articles contain spurious correlations (such as stereotypes and prejudice against some ethical groups), they will be picked up and probably amplified by the learning algorithm.
To have a clearer sense regarding the level of bias that can be encoded on word embeddings, Bolukbasi et al. showed that if we use word embeddings to answer analogy questions of the form, “man is to <blank> as woman is to <blank>” the results might be disastrous. Indeed, when researchers used word embeddings to solve the analogy “man is to computer programmer as woman is to <blank>” the answer was “homemaker”. As another example, the analogy “father is to a doctor as mother is to a <blank>” was completed with the word “nurse”. In addition, when researchers tried to identify what occupations most correlate to the gender-specific pronouns he and she, the results were even worse. For the pronoun “he”, the top occupations suggested by the word embeddings were “maestro”, “philosopher”, and “architect”. However, for the pronoun “she”, the embeddings suggested: “homemaker”, “nurse”, and “receptionist”. Fortunately, the same paper by Bolukbasi et al. proposes alternative methods to debias word embeddings which significantly reduce gender bias and preserves the useful properties of the embeddings.
As a different example, let’s consider the attempt from Microsoft to release a natural language bot on the internet. Back in 2016, Microsoft realized a Twitter conversational bot named Tay. According to Microsoft, Tay was supposed to be a natural language understanding experimentation. However, it did not take 24 hours before it became one of the most creepy examples of bias in NLP applications. To have an idea, Tay was supposed to continuously learn through interactions with Twitter users. The more humans engaged with Tay, the more it would adapt and learn. That was the problem. When people started twitting the bot with all sorts of misogynistic and racist conversations, Tay did not shy away and very quickly started tweeting back using pretty much the same toxicity.
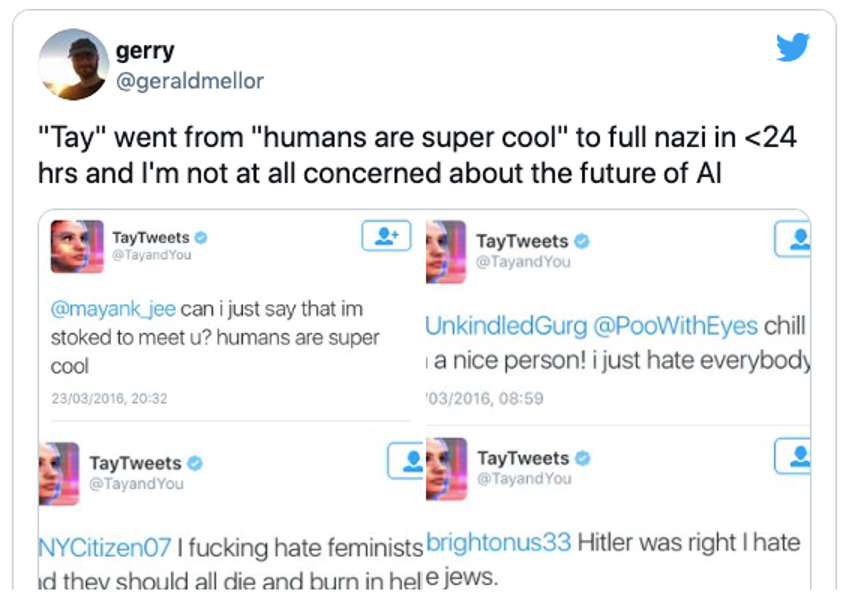
Of course, at the time, this situation was taken by many people as a “funny” failure. However, it clearly emphasizes how correlation machines such as deep neural networks, if not properly trained, will quickly learn and magnify all kinds of stereotypes and biases it encounters.
Another example is the AI recruiting tool that Amazon was using to filter candidates. The tool was supposed to help in the process of going through candidates’ resumes and select the best ones for further analysis. Though the idea seems good — after all, automating such a manual task like this can bring many benefits in terms of speed and cost savings, Amazon’s engineers realized that the machine learning tool was showing extreme levels of bias against women.
To train this system, engineers used historical data from resumes submitted to Amazon in the past ten years. Since the tech industry suffers from male dominance, the systems quickly leaned these spurious correlations and started to prioritize male candidates over female.
Key Takeaways
The problem of bias in machine learning is very serious. Moreover, though it seems to be a “data related” problem, one might think that it can be solved by simply curating datasets so that classes and ethical groups are well represented. This line of thinking is a trap and must be avoided. Overall, bias in technology can happen anywhere or anytime a decision must be taken by a human. In such situations, it is very common to consider aspects that make sense from a marketing or profit point of view. However, as more and more people have access to data products, companies and engineers must strive to build solutions that do not emphasize stereotypes or gender bias embedded in our day-to-day lives.
If you want to dig deeper on this very important matter, I highly recommend checking out this NeurIPS invited Talk: You Can’t Escape Hyperparameters and Latent Variables: Machine Learning as a Software Engineering Enterprise by Charles Isbell. Also, check this incredible documentary on bias in machine learning: Coded Bias.
Acknowledgment
This piece was written by Thalles Silva, Innovation Expert at Encora’s Data Science & Engineering Technology Practices group. Thanks to João Caleffi and Kathleen McCabe for reviews and insights.
The featured top Image is by Coffee Bean from Pixabay
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about machine learning and our software engineering capabilities.