How can we train machine learning models using distributed sensitive data?
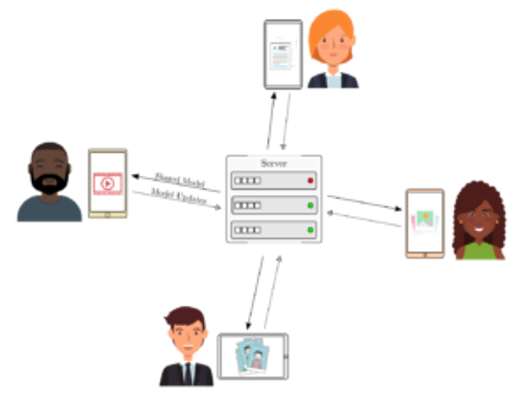
Federated Learning is a machine learning framework that allows data scientists to train statistical models using sensitive data from users, without uploading user data to servers. It is a distributed training technique where training and testing occur locally (at the edge) and only the meta-information is sent to a central server that combines multiple model updates (from multiple clients) into a new model.
We all have experienced the benefits of crowdsourcing. In mobile apps such as Waze, clients using the platform can report all sorts of driving conditions such as car crashes, traffic jams, police speed traps, cars parked on the side of the road, etc. In turn, other users can take advantage of such collaboration to make better driving decisions. As a simple example, if there is an intense traffic jam on a given road, Waze might choose a different route to reach the destination.
Similarly, when looking for a hotel to stay the next family holiday, we usually read multiple reviews from previous customers. We can discover nearly everything on platforms such as TripAdvisor or Booking.com, from how neat the place is, to how the staff treats customers and much more.
Lastly, it is relatively common to use crowdsourcing tools such as the Amazon Mechanical Turk to accelerate machine learning development. The idea is to take advantage of a highly distributed platform to outsource a given process. This process is broken down into independent and simple tasks that non-experts can perform in a few minutes. Such tasks might include data annotation, validation, or simple data cleaning procedures such as deduplication.
What if we could take advantage of the very same properties of crowdsourcing to solve important machine learning problems?
That is the idea behind Federated Learning.
Hospitals and big corporations are trying to figure out how to use large quantities of sensitive data to improve their services. Imagine, for instance, if we could use all the available data from hospitals worldwide to train machine learning systems. Applications such as a melanoma diagnosis or breast cancer diagnosis would surely benefit from this collaboration. The same reasoning applies to Insurance and Banking companies that could take advantage of sensitive data to build more reliable predictive models. However, the main barrier preventing us from doing this collaborative work towards better healthcare is another essential concern — privacy.
As predictive models become prevalent in our daily lives, the concern of how companies worldwide can use our data increases. It does not feel right knowing that companies can take the data we generate, and without our approval, use it to train commercialized machine learning algorithms. Moreover, it is not conceivable (from a privacy standpoint) that a hospital can take the images from your last exam and hand them to an overseas company that will create predictive models. That is why regulations like HIPAA and GDPR exist to ensure that clients’ data is privately preserved at all costs.
We can view Federated Learning as crowdsourcing the machine learning pipeline
Like crowdsourcing, Federated Learning aims to take advantage of multiple participants that can contribute to a global task individually. In this game, the participants can be all sorts of devices, not only smartphones and tablets but also self-driving cars, healthcare data located in hospitals, or any computing device connected to the internet containing both, users’ interaction data and enough processing power.
The data within each client’s device has unique properties. To begin with, it is highly personal. Imagine a smartphone virtual keyboard application. Users employ mobile keyboards daily to talk to friends, fill documents, and interact with coworkers. In this process, they type passwords, send audio messages, expose private information about themselves or the company they work for, talk to their doctors, etc. But this data is also highly unbalanced across participants. It is easy to see that people may use the keyboard at different rates for different things. While a given user solves all of her bank problems through the mobile app, other users might prefer to go to the bank’s physical location.
As another example, consider a driving assistant mobile application such as Waze or Google Maps. Again, the kind of data generated every time we use such applications is highly sensitive. It can be used to know every place a person has visited, whether they are/were driving a car, in a flight, walking at the park, or riding a bike. Moreover, one can use it to train statistical models that can learn the patterns of movement of any person. These models could be used to predict the places where he/she is likely to go tomorrow afternoon or next weekend. It is a significant breach of privacy.
Federated Learning
Federated Learning is a technique designed to train scaled machine learning models, using on-device data in a privately preserved manner. Presented in the 2015 paper “Communication-Efficient Learning of Deep Networks from Decentralized Data” by Google researchers, Federated Learning is a distributed algorithm for training a centralized model on decentralized data.
One of the key aspects of Federated Learning is that it decouples machine learning training from the necessity of having a dataset stored in a central server. In Federated Learning, the data never leaves the users’ devices. Training of machine learning models occurs locally, using the device’s computing power and data. Only the training meta-information (weights and biases) from the locally trained model is transferred to a central server.
To understand Federated Learning, we need to explore how it differs from standard machine learning development. Indeed, applying Federated Learning requires a different way of thinking.
When building machine learning models, it is common to aggregate the training and validation data in a central place like a server. With all the data in a single location, tasks like data exploration, visualization, validation, and batch training techniques (used for deep neural networks) can be done quickly and reliably.
Most machine learning algorithms assume the data is IID (Independently and Identically Distributed). Federated Learning breaks this rule. Here, each participant only holds data from its utilization. Therefore, we cannot assume that each portion of data (from each client device) represents the entire population. In Federated Learning, model development, training, and evaluation occur without direct access to the raw data. However, communication costs and reliability are major limiting factors.
It works like this. From a pool of candidates, the algorithm chooses a subset of eligible participants based on some heuristics. If we constrain our example to mobile devices (smartphones and tablets), the set of eligible devices would be those: fully charged, with specific hardware configurations, connected to a reliable and free WiFi network, and idle. Here is one important property of the Federated Learning framework — not all devices participate in the federation. Only eligible devices receive a training model. The reason is to minimize the negative impact that local training could have on the users’ experience. If we conceive that a local training might last a few minutes, no one would be pleased to experience a lagging device (due to training of the local model) when using the device to talk to a friend or to fetch a piece of important information.

The FederatedAveraging pseudo-algorithm
Each participant in the set of eligible devices receives a copy of the global or training model. Then, each device starts a local fine-tuning process of the training model using the local data. After training, the updated parameters from each local model are sent to the central server for a global update.
The Federated Averaging algorithm is depicted in the pseudo-algorithm above. It is divided into two pieces, one executed by the server and the other by the clients. In the beginning, the server initializes the model parameters — usually with random values. The server coordinates different rounds of execution. At each round, the server randomly chooses a set of clients (the eligible devices) and, in parallel, sends a copy of the training model. To fine-tune the copy of the training model, each client performs a series of gradient descent steps using its data. After training, each client sends back the weights and biases of the local model to the server. The server aggregates the updates from all clients and starts a new round.
It is important to note that Federated Learning alone is not privately secured. Since the individual model updates from each device are sent to a coordinating server, an attacker (or even the server) could access the raw updates and make some reverse engineering to review information about each client’s data. For this reason, typical Federated Learning employs end-to-end encryption. In this way, the training metadata is encrypted when moving from client to server, which adds a layer of security to this process.
To prevent the server from having access to the raw updates, a method called secure aggregation allows the server to combine the encrypted models from several participants and only decrypt the aggregated training results. In this way, the server never sees the training results from a particular device. Moreover, we can integrate Federated Learning with Differential Privacy for increased security.
Besides training, another fundamental difference between Federated and regular machine learning is testing. In machine learning, we should validate models using data that resembles the most what the model will see in production. However, since the server does not have access to the training data, it cannot test the combined model after updating it using the clients’ contributions. For this reason, training and testing occur on users’ devices. Note that distributed testing brings back the benefits of testing the new version of the model where it matters the most, that is, on the users’ devices.

Conclusions
Federated Learning is a new technique that has incredible potential. It is a collaborative and decentralized approach that allows scientists to train machine learning models using sensitive data following privacy standards. With the recent advances in 5G technology, we will rely on more stable and faster internet connections, which in turn have the potential to boost the number of applications where we can employ Federated Training. Even though Federated Learning is still young, many successful cases, such as the Google virtual Keyboard (GBoard) and Apple Siri, already prove the benefit of this approach.
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.